
 I love granola.ai. Everyone I know is using it for meeting transcription. I’ve been using it to transcribe my calls and meetings for months.
I love granola.ai. Everyone I know is using it for meeting transcription. I’ve been using it to transcribe my calls and meetings for months.
But I want my notes in one place, and I use Obsidian. I love that it uses plaintext files, auto-renders markdown, and has vim-motion support.
I wanted all my Granola notes to get into Obsidian somehow. Here’s the story how I made that happen (and a script for you to do the same at the end).
The first thing I tried was asking Granola if there was an API or a way to find the notes on disk. They have a sync for Notion already. They said they don’t have an API, and I did get a few direct messages about where to look on disk from a few other users.
I actually never found the notes on disk, but I did find what I was looking for.
Proxying Granola
So, being the hackerman that I am, I decided to proxy the Granola API and see if I could reverse engineer the way the desktop app gets the notes. So I set my system proxy to point to Caido and started using Granola. Voila:
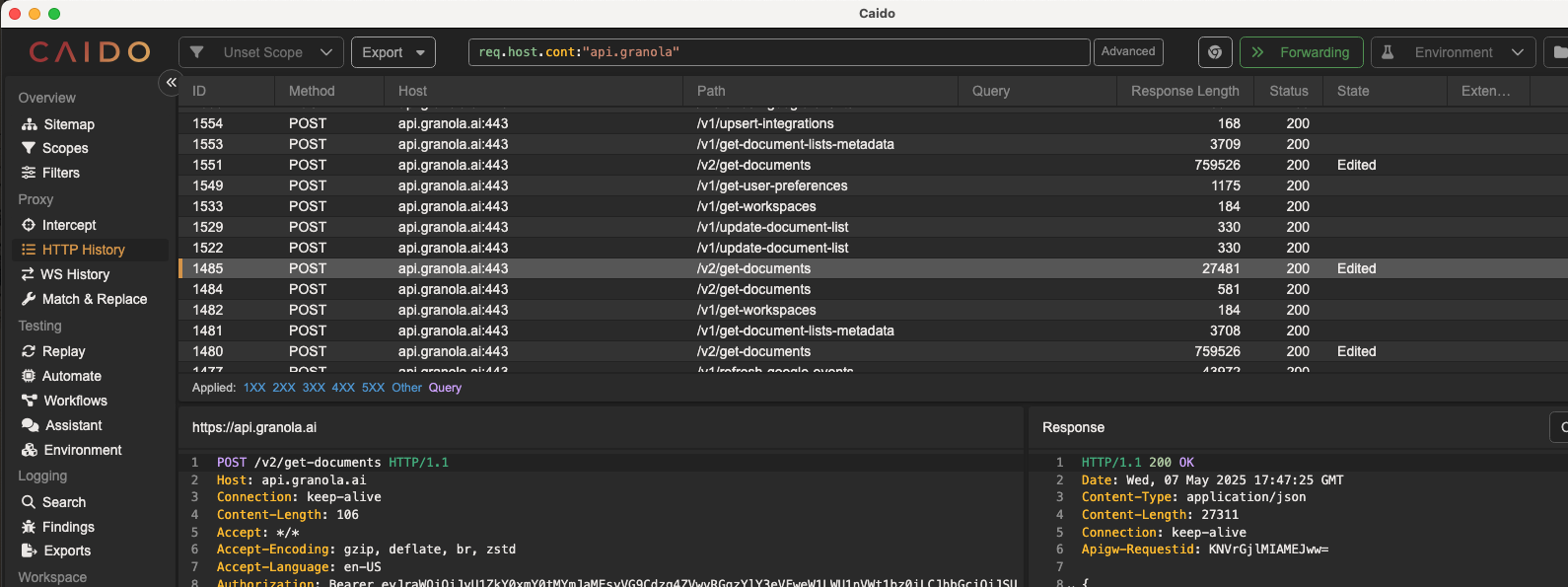
The get-documents endpoint is the one that holds the notes! 😊
Figuring out Auth
I knew the API had to require credentials. It uses a Bearer token. So I grepped through my filesystem and found the supabase.json credential file on my disk at Library/Application Support/Granola/supabase.json. With these credentials, I knew I could pull the notes from the API.
The Python Script
So I just had the new Gemini 2.5 pro whip me up the script below. It pulls the notes into a folder of your choosing as markdown files (naturally, I picked a folder in my Obsidian vault). It saves the summarized notes only, not the transcript. If you want it to pull the transcripts also, I’ll leave that as an exercise for the reader.
import argparse
import logging
from pathlib import Path
import traceback
import json
import os
import requests
from datetime import datetime
# Configure logging
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('granola_sync.log'),
logging.StreamHandler()
]
)
logger = logging.getLogger(__name__)
def load_credentials():
"""
Load Granola credentials from supabase.json
"""
creds_path = Path.home() / "Library/Application Support/Granola/supabase.json"
if not creds_path.exists():
logger.error(f"Credentials file not found at: {creds_path}")
return None
try:
with open(creds_path, 'r') as f:
data = json.load(f)
# Parse the workos_tokens string into a dict
workos_tokens = json.loads(data['workos_tokens'])
access_token = workos_tokens.get('access_token')
if not access_token:
logger.error("No access token found in credentials file")
return None
logger.debug("Successfully loaded credentials")
return access_token
except Exception as e:
logger.error(f"Error reading credentials file: {str(e)}")
return None
def fetch_granola_documents(token):
"""
Fetch documents from Granola API
"""
url = "https://api.granola.ai/v2/get-documents"
headers = {
"Authorization": f"Bearer {token}",
"Content-Type": "application/json",
"Accept": "*/*",
"User-Agent": "Granola/5.354.0",
"X-Client-Version": "5.354.0"
}
data = {
"limit": 100,
"offset": 0,
"include_last_viewed_panel": True
}
try:
response = requests.post(url, headers=headers, json=data)
response.raise_for_status()
return response.json()
except Exception as e:
logger.error(f"Error fetching documents: {str(e)}")
return None
def convert_prosemirror_to_markdown(content):
"""
Convert ProseMirror JSON to Markdown
"""
if not content or not isinstance(content, dict) or 'content' not in content:
return ""
markdown = []
def process_node(node):
if not isinstance(node, dict):
return ""
node_type = node.get('type', '')
content = node.get('content', [])
text = node.get('text', '')
if node_type == 'heading':
level = node.get('attrs', {}).get('level', 1)
heading_text = ''.join(process_node(child) for child in content)
return f"{'#' * level} {heading_text}\n\n"
elif node_type == 'paragraph':
para_text = ''.join(process_node(child) for child in content)
return f"{para_text}\n\n"
elif node_type == 'bulletList':
items = []
for item in content:
if item.get('type') == 'listItem':
item_content = ''.join(process_node(child) for child in item.get('content', []))
items.append(f"- {item_content.strip()}")
return '\n'.join(items) + '\n\n'
elif node_type == 'text':
return text
return ''.join(process_node(child) for child in content)
return process_node(content)
def sanitize_filename(title):
"""
Convert a title to a valid filename
"""
# Remove invalid characters
invalid_chars = '<>:"/\\|?*'
filename = ''.join(c for c in title if c not in invalid_chars)
# Replace spaces with underscores
filename = filename.replace(' ', '_')
return filename
def main():
logger.info("Starting Granola sync process")
parser = argparse.ArgumentParser(description="Fetch Granola notes and save them as Markdown files in an Obsidian folder.")
parser.add_argument("output_dir", type=str, help="The full path to the Obsidian subfolder where notes should be saved.")
args = parser.parse_args()
output_path = Path(args.output_dir)
logger.info(f"Output directory set to: {output_path}")
if not output_path.is_dir():
logger.error(f"Output directory '{output_path}' does not exist or is not a directory.")
logger.error("Please create it first.")
return
logger.info("Attempting to load credentials...")
token = load_credentials()
if not token:
logger.error("Failed to load credentials. Exiting.")
return
logger.info("Credentials loaded successfully. Fetching documents from Granola API...")
api_response = fetch_granola_documents(token)
if not api_response:
logger.error("Failed to fetch documents - API response is empty")
return
if "docs" not in api_response:
logger.error("API response format is unexpected - 'docs' key not found")
logger.debug(f"API Response: {api_response}")
return
documents = api_response["docs"]
logger.info(f"Successfully fetched {len(documents)} documents from Granola")
synced_count = 0
for doc in documents:
title = doc.get("title", "Untitled Granola Note")
doc_id = doc.get("id", "unknown_id")
logger.info(f"Processing document: {title} (ID: {doc_id})")
content_to_parse = None
if doc.get("last_viewed_panel") and \
isinstance(doc["last_viewed_panel"], dict) and \
doc["last_viewed_panel"].get("content") and \
isinstance(doc["last_viewed_panel"]["content"], dict) and \
doc["last_viewed_panel"]["content"].get("type") == "doc":
content_to_parse = doc["last_viewed_panel"]["content"]
logger.debug(f"Found content to parse for document: {title}")
if not content_to_parse:
logger.warning(f"Skipping document '{title}' (ID: {doc_id}) - no suitable content found in 'last_viewed_panel'")
continue
try:
logger.debug(f"Converting document to markdown: {title}")
markdown_content = convert_prosemirror_to_markdown(content_to_parse)
# Add a frontmatter block for metadata
frontmatter = f"---\n"
frontmatter += f"granola_id: {doc_id}\n"
escaped_title_for_yaml = title.replace('"', '\\"')
frontmatter += f'title: "{escaped_title_for_yaml}"\n'
if doc.get("created_at"):
frontmatter += f"created_at: {doc.get('created_at')}\n"
if doc.get("updated_at"):
frontmatter += f"updated_at: {doc.get('updated_at')}\n"
frontmatter += f"---\n\n"
final_markdown = frontmatter + markdown_content
filename = sanitize_filename(title) + ".md"
filepath = output_path / filename
logger.debug(f"Writing file to: {filepath}")
with open(filepath, 'w', encoding='utf-8') as f:
f.write(final_markdown)
logger.info(f"Successfully saved: {filepath}")
synced_count += 1
except Exception as e:
logger.error(f"Error processing document '{title}' (ID: {doc_id}): {str(e)}")
logger.debug("Full traceback:", exc_info=True)
logger.info(f"Sync complete. {synced_count} notes saved to '{output_path}'")
if __name__ == "__main__":
main()
More work/research
There are two things that I could see come of this post, if any readers want something to do. One, someone could easily turn this into an Obsidian plugin. Two, I think there’s lots of interesting things to look at in the Granola API.
- Joseph
Sign up for my email list to know when I post more content like this. I also post my thoughts on Twitter/X.
